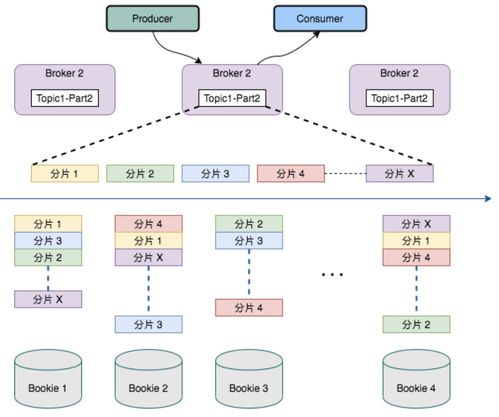
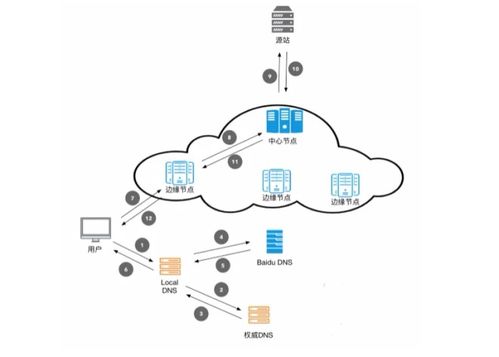
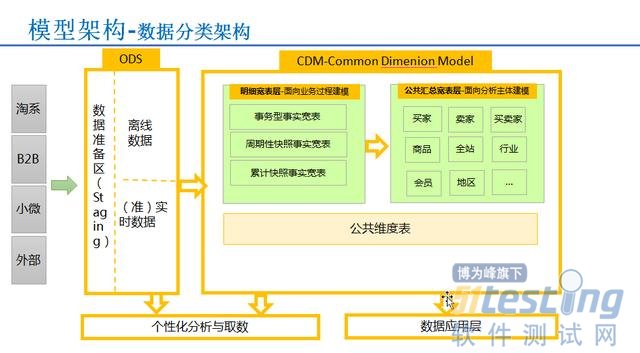
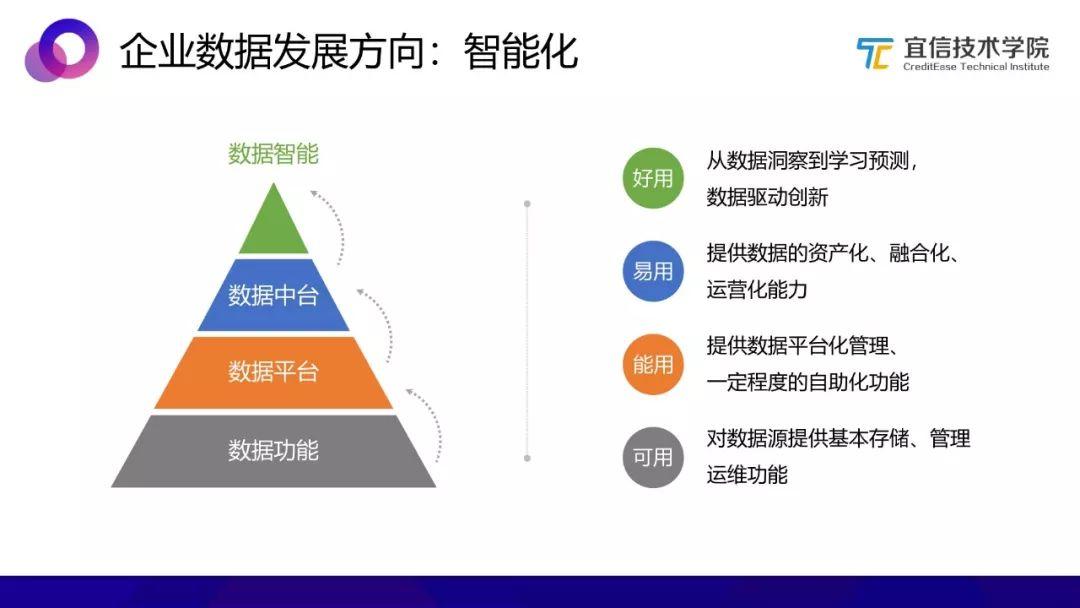
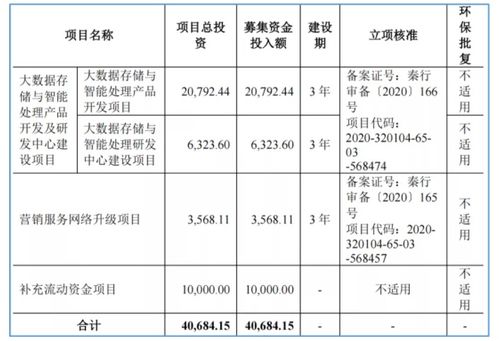
数据处理与存储支持服务 图解技术原理,让复杂变简单
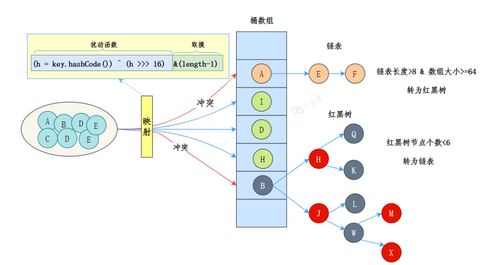
在当今数据驱动的时代,高效、可靠的数据处理和存储支持服务已成为企业数字化转型的基石。这些服务背后的技术原理往往因其专业性而显得深奥难懂。幸运的是,通过直观的图解方式,我们可以清晰地揭示其核心机制,理解其如何为各类应用提供强大支撑。这不仅是技术普及的有效途径,也让我们由衷赞叹现代IT架构设计的精妙。
一、 数据处理服务的核心原理图解
数据处理服务主要负责对海量、多源、异构的原始数据进行采集、清洗、转换、分析和计算,最终提取出有价值的信息。其典型技术栈与流程可通过一个分层管道图来形象展示:
- 数据摄入层:图示中,各种数据源(如数据库日志、IoT设备传感器、用户点击流、第三方API)像多条溪流,通过Kafka、Flume等“数据管道”汇集到中央湖/仓。箭头清晰表明了数据的流向。
- 存储与批处理层:通常用一座分层的数据湖或数据仓库图标表示。原始数据作为“湖水”存入(如HDFS、对象存储),其上方的“数据处理工厂”(如Spark、Flink图标)对数据进行批量清洗、转换(ETL),形成结构化的、可用的数据层。
- 实时处理层:一条与批处理并行的“高速数据流”管道尤为醒目。数据流经Flink、Spark Streaming等引擎,进行实时过滤、聚合与计算,结果直接输出到仪表盘或告警系统,体现了低延迟的特性。
- 分析与服务层:位于顶端,图表显示处理后的数据通过API或SQL接口,供给上层的BI工具(如饼图、曲线图图标)、AI模型(神经网络图标)和业务应用调用。
通过这样的图解,分布式计算、流批一体、弹性伸缩等抽象概念变得一目了然。
二、 数据存储支持服务的技术架构图解
数据存储服务是数据处理得以进行的前提,它确保数据持久、安全、可高效访问。其原理可以通过一个“存储金字塔”或“多模存储矩阵”图来阐释:
- 热数据高速缓存(金字塔顶端):用闪电图标代表Redis、Memcached等内存数据库,为高频访问数据提供亚毫秒级响应,显著减轻后端压力。
- 在线事务处理(金字塔上层):关系型数据库(如MySQL、PostgreSQL图标,常以表格形式出现)位于此层,通过ACID事务特性保障核心业务数据的强一致性。图解中通常会展示主从复制、分库分表等扩展架构。
- 在线分析处理与大数据存储(金字塔中层及基座):
- 数据仓库:如Snowflake、BigQuery的图标,专为复杂分析查询优化,采用列式存储结构(图示中数据垂直排列),与事务处理分离。
- 数据湖:如一个包容万象的“湖”的图标,内部可存放结构化、半结构化、非结构化原始数据,体现了其“模式在读时定义”的灵活性。底层常与HDFS、S3等低成本对象存储关联。
- 归档与冷存储(金字塔底层):用磁带库或冰川图标表示,用于存储极少访问的历史数据,成本极低。箭头表明数据可根据生命周期策略在不同层级间自动流动。
一张展示“多模数据库”的维恩图或矩阵图也很有说服力,它清晰划分了键值、文档、宽列、图等不同数据模型及其代表产品(如MongoDB、Cassandra、Neo4j),说明了为何要根据数据结构选择最佳存储。
三、 协同工作:支持服务的完美融合
数据处理与存储服务并非孤立运行。一张典型的“Lambda架构”或“Kappa架构”全景图能完美展示其协同:
- 图的左侧,实时数据流经流处理服务,计算结果存入一个高速的键值存储或OLAP数据库,以供实时查询。
- 图的右侧,同一份数据也落入数据湖/仓,由批处理服务进行更全面、精准的校正与计算,形成“黄金数据集”。
- 通过统一的数据服务层或元数据管理(图中像一个“大脑”或“目录”),为上层应用提供一致的数据视图。
****
图解的力量在于化繁为简,将复杂的技术原理转化为直观的视觉逻辑。通过上述图解,我们不仅看懂了数据处理如何像一条精密的流水线将原始数据转化为洞见,也理解了数据存储如何像一个智能分层的仓库系统确保数据各得其所、随时可用。这种清晰的理解,让我们能够更好地设计、选用和运维这些服务,从而真正释放数据的巨大潜能。数据处理与存储支持服务,图解其原理,确实“真的太赞了”。
如若转载,请注明出处:http://www.opulencespring.com/product/76.html
更新时间:2026-06-19 15:00:40