湖仓一体技术调研 Apache Hudi、Iceberg与Delta Lake在数据处理与存储支持服务上的对比分析
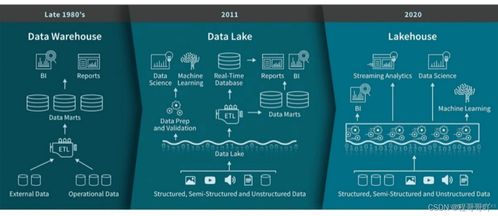
随着数据湖架构在企业中的广泛应用,数据管理与查询效率的挑战日益凸显。湖仓一体(Lakehouse)作为一种新兴的数据架构范式,旨在融合数据湖的灵活性与数据仓库的高性能管理能力。在这一领域,Apache Hudi、Apache Iceberg和Delta Lake已成为三大主流开源解决方案,它们均提供了ACID事务、数据版本控制、模式演进等关键特性,但在设计哲学、数据处理能力和存储支持服务上存在差异。本文将对这三者进行综合对比分析,以期为技术选型提供参考。
一、核心特性与设计哲学概述
- Apache Hudi
- 设计目标:专注于实时数据湖的增量处理,强调低延迟的数据更新和删除能力,特别适用于需要近实时数据摄入和变更数据捕获(CDC)的场景。
- 关键特性:支持插入、更新、删除操作;提供两种表类型(Copy-on-Write和Merge-on-Read);内置索引机制加速数据定位。
- Apache Iceberg
- 设计目标:致力于提供高性能、可扩展的表格式抽象,强调查询优化和跨引擎兼容性,适合大规模分析工作负载。
- 关键特性:隐藏分区、模式演进、快照隔离;通过元数据层实现高效的数据剪枝和谓词下推。
- Delta Lake
- 设计目标:由Databricks主导,旨在为Apache Spark提供可靠的数据湖存储层,强调事务一致性与数据质量管控。
- 关键特性:ACID事务、数据版本历史、数据验证(Schema Enforcement)和时间旅行(Time Travel)。
二、数据处理能力对比
- 数据更新与删除
- Hudi:通过索引支持高效的更新/删除,适合频繁变更的场景。Merge-on-Read模式可平衡读写性能。
- Iceberg:支持行级更新和删除,但依赖于引擎实现(如Spark 3.0+),更侧重于批量处理优化。
- Delta Lake:提供完整的更新/删除接口,与Spark深度集成,操作较为直观。
- 查询性能
- Hudi:索引加速点查和增量查询;Merge-on-Read可能增加读取开销。
- Iceberg:通过元数据优化(如分区演化、文件统计)大幅提升扫描效率,适合复杂分析查询。
- Delta Lake:利用数据统计和索引优化查询,但性能高度依赖Spark优化器。
- 流批一体支持
- Hudi:原生支持流式写入和增量拉取,与Flink、Spark Streaming集成良好。
- Iceberg:通过“快照”概念支持流式读取,但流写入需依赖引擎适配。
- Delta Lake:提供结构化流处理集成,支持连续处理和批处理统一。
三、存储支持与服务生态
- 存储兼容性
- 三者均支持云对象存储(如AWS S3、Azure Blob Storage、Google Cloud Storage)和HDFS,但实现细节不同:
- Hudi:对云存储有专门优化(如一致性保证)。
- Iceberg:通过原子操作抽象层减少存储依赖。
- Delta Lake:依赖事务日志保证一致性,对云存储有较好适配。
- 计算引擎集成
- Hudi:支持Spark、Flink、Hive、Presto/Trino等,生态较为开放。
- Iceberg:设计为引擎无关,已集成Spark、Flink、Trino、Hive、Impala等,兼容性最广。
- Delta Lake:深度绑定Spark,对其他引擎支持需通过第三方连接器(如Delta Standalone)。
- 管理与运维工具
- Hudi:提供命令行工具和元数据管理,但企业级功能较弱。
- Iceberg:拥有丰富的元数据API,易于构建自定义管理工具。
- Delta Lake:在Databricks平台内提供完善的UI、监控和优化服务,开源版本功能相对有限。
四、适用场景
- Apache Hudi:适用于需要近实时数据更新、CDC处理或增量管道的场景,如实时数仓、物联网数据处理。
- Apache Iceberg:适合大规模数据分析、多引擎共享数据的场景,特别是对查询性能和分区灵活性要求较高的企业。
- Delta Lake:适合以Spark为核心的技术栈,强调数据质量与事务一致性,且可受益于Databricks商业支持的环境。
五、结论
Apache Hudi、Iceberg和Delta Lake均推动了湖仓一体架构的成熟,但各有侧重。Hudi在实时处理上表现突出,Iceberg在查询优化和跨引擎兼容性上更具优势,而Delta Lake则提供了与Spark生态的最优集成。企业在选型时需综合考虑现有技术栈、数据场景(流批比例、更新频率)和长期维护成本。随着湖仓一体标准化进程的推进,三者可能会进一步融合或形成互补生态,为用户提供更统一的数据管理体验。
如若转载,请注明出处:http://www.opulencespring.com/product/64.html
更新时间:2026-06-19 12:46:31