腾讯看点多维实时分析系统架构揭秘 数据处理与存储的强力支撑
在信息爆炸的时代,腾讯看点作为重要的内容分发平台,面临着海量用户行为数据的实时处理与分析挑战。其背后支撑的多维实时分析系统,凭借先进的数据处理与存储架构,实现了对亿级用户行为的毫秒级洞察,为个性化推荐、运营决策和产品优化提供了坚实的数据基础。
一、系统架构概览:分层设计与流批一体
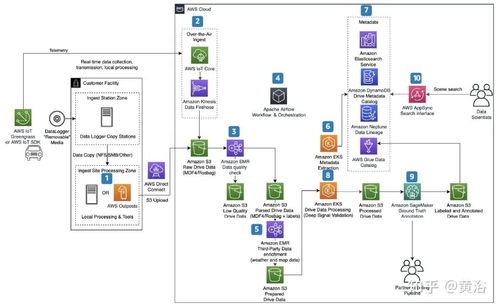
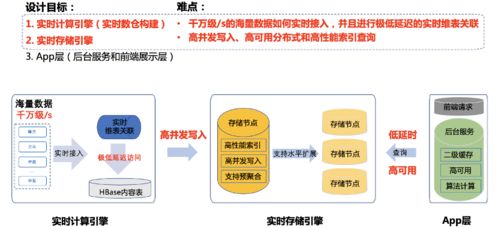
腾讯看点多维实时分析系统采用分层、模块化的设计理念,整体架构可分为数据采集层、实时处理层、存储服务层和应用服务层。
- 数据采集层:作为数据入口,通过轻量级SDK和日志采集Agent,以高吞吐、低延迟的方式,从客户端、服务器端全链路收集用户点击、浏览、停留、分享等行为事件,并进行初步的过滤与格式化。
- 实时处理层(核心引擎):这是系统的“大脑”。基于Apache Flink构建的流式计算引擎是核心,它负责对源源不断的数据流进行实时清洗、关联、聚合与复杂事件处理。系统实现了“流批一体”的设计,同一套计算逻辑可同时支持实时流处理和离线批量补算,保障了数据口径的一致性与计算的灵活性。
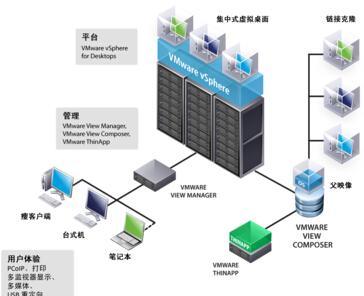
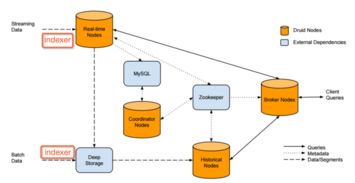
- 存储服务层(基石支撑):针对不同分析场景对数据新鲜度、查询效率、存储成本的差异化要求,系统构建了混合存储体系:
- 实时聚合结果存储:使用高性能的KV存储(如Redis/自研系统)和时序数据库,存放秒级/分钟级的最新聚合指标,供实时监控和大屏展示。
- 明细数据查询存储:采用列式存储数据库(如ClickHouse或Apache Druid),支持对近期明细数据的快速多维筛选与即席查询(Ad-hoc Query)。
- 长期冷数据存储:依托腾讯云对象存储(COS)或HDFS,以极低的成本存储全量历史明细数据,供深度回溯分析与模型训练。
- 应用服务层:提供统一的查询网关和API服务,将底层复杂的存储封装成简单的接口,向推荐系统、运营平台、数据分析师等输出实时画像、趋势报表和自定义分析结果。
二、数据处理的核心:高吞吐、低延迟与精准一致
面对每日千亿级的事件洪流,系统的数据处理能力经受着严峻考验。
- 高性能流处理:利用Flink的状态管理和精确一次(Exactly-Once)语义保障,即使在发生故障时也能确保计数、求和等聚合结果的准确性。通过窗口优化、旁路输出(Side Output)等技术,灵活支撑从秒级到天级的多种时间维度的聚合计算。
- 维度管理:建有统一的维度服务中心,管理用户、内容、渠道等所有维度信息。在流处理过程中实时进行维度关联(如将设备ID关联到用户ID),确保分析视角的完整性和准确性。
- 数据质量保障:在管道中设立多个质量监测点,对数据格式、完整性、合理性进行实时校验与告警,并具备死信队列(Dead Letter Queue)机制处理异常数据,保证进入下游的数据干净可靠。
三、存储服务的智慧:多模混合与智能调度
存储层并非简单堆砌,而是通过智能的数据生命周期管理与路由策略,实现成本与性能的最优平衡。
- 分层存储与自动降冷:数据根据其时间价值和访问频率自动流动。例如,秒级聚合结果存于内存,过去一小时的明细存于ClickHouse,一天前的明细则自动转存至对象存储。这套策略由系统自动调度,对上层应用透明。
- 统一查询服务:开发了统一的查询引擎,能够理解查询语句的时间范围、维度组合和聚合程度,自动判断应从哪个存储层(热存储或冷存储)获取数据,甚至进行跨层数据合并,对用户提供“一个入口,全量数据”的查询体验。
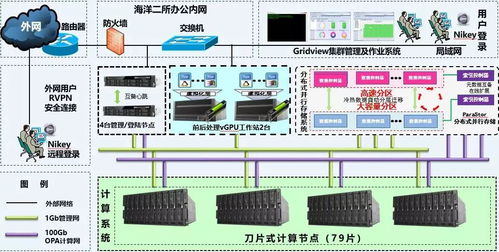
- 高可用与扩展性:存储层各个组件均采用分布式集群部署,具备水平扩展能力,可随数据量增长弹性扩容。通过多副本机制和跨可用区部署,保障服务的高可用性和数据持久性。
四、与展望
腾讯看点多维实时分析系统的成功,关键在于其以流处理为核心、混合存储为基石、统一服务为接口的协同架构。它不仅在技术上实现了海量数据的实时化、精准化分析,更在业务上驱动了产品体验的快速迭代和运营效率的极大提升。
随着数据规模持续膨胀和分析场景日益复杂,系统将继续在存算分离、AI增强的实时分析(如实时异常检测、预测)以及更智能的成本优化等方面进行深度探索,以构建更敏捷、更经济、更智能的新一代实时数据基础设施,持续赋能业务增长。
如若转载,请注明出处:http://www.opulencespring.com/product/49.html
更新时间:2026-06-19 19:50:07